
Применение методов машинного обучения для работы с биологическими данными развивается стремительными темпами. В Научном центре мирового уровня «Центр персонализированной медицины» (НЦМУ) сформирована команда сотрудников, которые уже имеют опыт разработки методов идентификации генов, связанных с полигенными заболеваниями, на основе результатов GWAS (полногеномного поиска ассоциаций).
В рамках новых проектов на базе НЦМУ специалистами начата разработка методов на основе машинного обучения для прогнозирования манифестации заболеваний и персонификации ведения пациентов. Ведется сбор клинических данных — основы для тренировки моделей и последующей валидации результатов, которые станут доступны всем клиническим центрам в Российской Федерации.
Для большинства заболеваний тактика ведения пациентов основана на сборниках рекомендаций и стандартов, разрабатываемых органами системы здравоохранения. В такой список рекомендаций обычно входят практики, оптимизированные с учетом текущих знаний о природе заболевания и накопленном опыте лечения. С каждой новой редакцией клинические подходы к ведению и терапии призваны улучшать эффективность медицинского вмешательства.
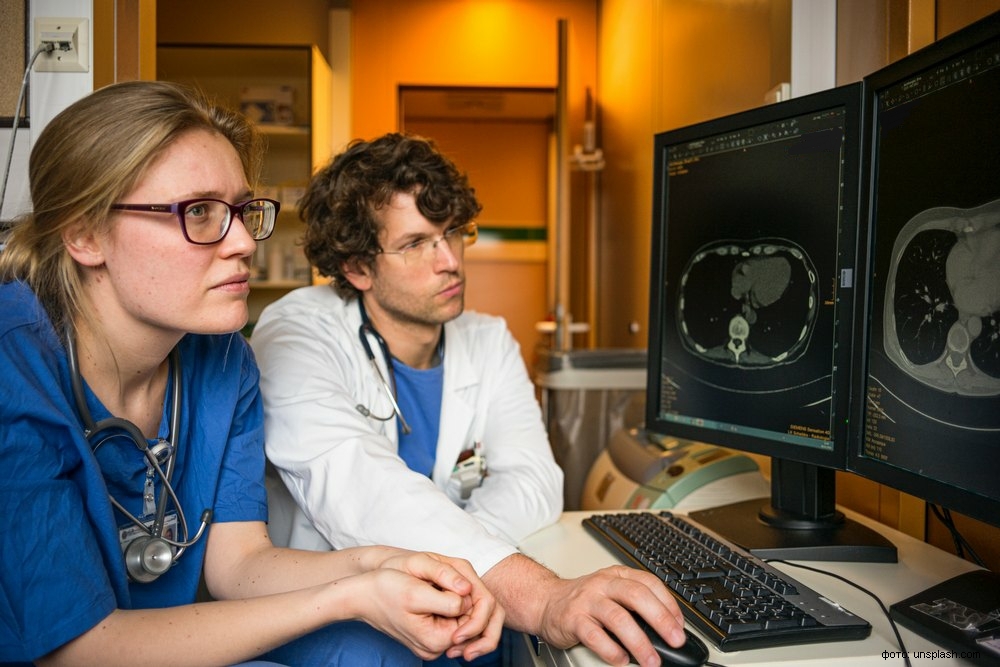
Методы машинного обучения основаны на схожем принципе — тренировке статистической модели на накопленных экспериментальных данных. В мировой практике машинное обучение в последние годы нашло широкое применение в анализе снимков КТ, маммографии, УЗИ. Зачастую анализ изображений с помощью компьютерных алгоритмов, совместно с опытом врачей, позволяет более точно распознать, к примеру, границы раковой опухоли и уточнить план оперативного вмешательства.